
ChatGPT Logistics
This blog utilizes ChatGPT as a key example to delve into the underlying logic behind all AI systems.

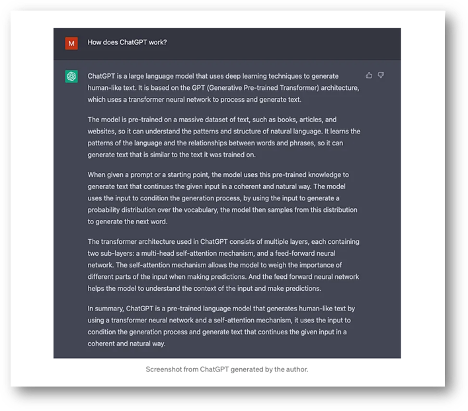
ChatGPT is an expansive conversational AI employing deep learning, machine learning, and big data methodologies to produce human-like text. Leveraging the Generative Pre-trained Transformer (GPT) architecture, users can insert text messages or prompts into ChatGPT. And ChatGPT will process these inputs using its Large Language Models (LLMs) (Floridi, 2023) and linguistic patterns, enabling the text generation of contextually relevant and coherent responses through a transformer neural system.
The transformer architecture is highly effective in capturing long-range dependencies in sequences by utilizing a self-attention mechanism to weigh the importance of different words regardless of their distance in the sequence. “Language models are probability distributions over a sequence of words.” In hence, making it particularly intelligent and highly adaptive at understanding and generating human-like text.
The LLMs possess significant power and versatility in executing diverse natural language processing tasks, which allows ChatGPT to act as a conversational partner, providing responses that are tailored to the user's queries, statements. Additionally, ChatGPT can adapt its responses based on the ongoing conversation, maintaining coherence and relevance throughout the interaction. The ChatGPT model's capability to comprehend and respond to a broad spectrum of topics and inquiries is derived from its exposure to diverse linguistic structures and contexts throughout its training process.
ChatGPT indeed represents a significant advancement in statistical based natural language processing (NLP), which “integrates computational linguistics and involves rule-based representation of human language. This fusion empowers computers and digital devices to perceive, comprehend, and produce.” In contrast to approaches reliant solely on manual rule-writing, statistical-based methods incorporate implicit rules within the model parameters. These rules are acquired through the model's training on data, eliminating the need for manual rule-writing.

These mechanisms show input messages and craft engaging and meaningful replies for the audience. This raises the question of “how these novel techniques have propelled ChatGPT to achieve exceptional performance levels, enabling it to generate responses that naturally and coherently correspond to the provided input.” Let us check it out more closely:
-
Deep Learning and Data Mining: ChatGPT effectively analyzes user input and generates sophisticated responses, thereby enhancing its role as a conversational agent and a versatile tool for natural language processing applications. Moreover, ChatGPT leverages data systems to set up inherent association rules, enabling it to predict next words in a sequence based on the provided context. This process not only helps gathering information from external sources but also contributes to the construction of its knowledge architecture.
-
Big Data: The computational ability distributed for training and inference tasks enhances ChatGPT's ability to efficiently process large volumes of data. By analyzing users' needs and using big data and statistical probabilities, it can provide performance predictions and tailored responses to users' queries. Notably, “GPT-3 is equipped with a 570 GB training dataset comprising books, articles, websites, and more.” This computational capability allows the model to analyze and understand complex language structures, thereby fostering the generation of coherent and contextualized relevant responses.
-
Pre-training: The concept of pre-training was first introduced by the “ELMO model (Embeddings from Language Models) and later adopted by various deep neural network models.” However, rather than directly learning how to address specific tasks, this model assimilates a broad spectrum of “information spanning grammar, lexicon, pragmatics, common sense, and knowledge, amalgamating them into the language model (Dwivedi Y., 2023).” This pre-training process allows the model to learn the intricacies of language, including syntax, semantics, and contextual understanding. Put simply, it functions more akin to a repository of knowledge rather than applying that knowledge to resolve practical problems.
-
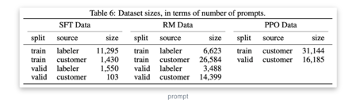
Human Training: Human training plays a vital role in the continuous improvement of ChatGPT models, solving certain limitations that may arise from initial pre-training on vast datasets of internet text. Human feedback is incorporated into the training process through result labeling. "The integration of prompts from the OpenAI API and manually written prompts by labelers yields 13,000 input/output samples, which are used to enhance the supervised model."
-
Predictive Modeling: ChatGPT processes the knowledge it gains from pre-training and later training sessions into an easily understandable format. To enhance the quality of responses, trainers not only rely on the first output provided by GPT but also show the desired outcomes and train on the model's output behavior, reinforcing predictive modeling techniques.
-
Feedback Loop: Through deep learning techniques, ChatGPT continuously learns and improves its responses. It can be trained with instructional phrases and receive feedback from humans, such as "good response," "bad response," or “requests to regenerate responses.” In programming, Boolean values (True or False) are indeed fundamental for decision-making, conditionals, and control flow structures like if statements and while loops. Python, like many programming languages, uses Boolean logic extensively for evaluation purposes as well. The feedback loop enables ChatGPT to iteratively refine its answer architecture and enhance its performance over time. This iterative process allows the model to effectively convey information to users with clarity and conciseness. Additionally, it empowers the model to adapt and improve its responses, aligning more closely with user needs and expectations.
The GPT model presents distinct and groundbreaking advantages. These include robust language comprehension capabilities, an extensive repository of knowledge, and adept learning and reasoning abilities. These attributes evoke the notion that artificial intelligence has a semblance of cognitive function, prompting considerations of employing GPT to address a wide array of challenges. While statistical-based methods are widely embraced, the primary drawback lies in the black-box uncertainty (Lin, Z., Trivedi, S., & Sun, J., 2023), “where rules are implicit and embedded within parameters.”
Nevertheless, a comprehensive understanding of the technology's limitations is imperative for its nuanced application, facilitating the mitigation of shortcomings while maximizing its potential benefits, there are certain limitations that may arise from the LLMs system (Bender et al., 2021; Bommasani et al., 2021; Kenton et al., 2021; Weidinger et al., 2021; Tamkin et al., 2021; Gehman et al., 2020), which include:
-
Limited Memory Capacity: ChatGPT can respond to users' consecutive questions, which are multi-turn dialogues characterized by interconnected information. The specific format is quite straightforward: upon the user's second input, the system automatically concatenates the input and output information from the earlier interaction, providing ChatGPT with a reference to the context of the earlier conversation. However, if a user engages in extensive conversations with ChatGPT, typically only the information from the most recent few rounds of dialogue is kept by the LLMs, while the details of earlier conversations are forgotten.
-
Hallucinations: The responses generated by GPT models inherently rely on probabilities. LLMs may generate content that appears coherent but lacks factual accuracy. Unlike traditional software development where inputs and outputs of interfaces are deterministic, GPT's responses show a degree of randomness based on the input prompt. While this uncertainty may stimulate discussion when utilizing ChatGPT as a chat tool, it causes meticulous attention to mitigate uncertainty in commercial software applications. In most product scenarios, users prioritize deterministic outcomes. This could be due to the model's inability to discern information from the training data.
-
Bias: LLMs can inadvertently “reflect and even amplify biases present in the data they are trained on.” For instance, ChatGPT might yield ambiguous or unclear outcomes, or display biases originating from the developers who created its underlying code. This can make it difficult to discern the rationale behind it based solely on the results themselves.
-
Toxicity: LLMs might generate text that is offensive, harmful, or inappropriate. This could include hate speech, profanity, or other forms of toxic content.
-
Misinformation: LLMs can inadvertently propagate false information, especially if they are prompted to generate text on topics where the training data has inaccuracies or misinformation.
-
Misinterpretation of Instructions: Sometimes, LLMs may misinterpret user instructions or prompts, leading to unexpected or undesired outputs.
Addressing these challenges requires a multi-faceted approach involving careful curation of training data, continuous monitoring, and evaluation of model outputs, implementing safeguards within the models themselves, and promoting responsible usage of LLMs within the broader community.
Sources:
-
Floridi, L. AI as Agency Without Intelligence: on ChatGPT, Large Language Models, and Other Generative Models. Philos. Technol. 36, 15 (2023). https://doi.org/10.1007/s13347-023-00621-y
-
Ray, P. P. (2023). ChatGPT: A comprehensive review on background, applications, key challenges, bias, ethics, limitations and future scope. Internet of Things and Cyber-Physical Systems, 3, 121–154. https://doi.org/10.1016/j.iotcps.2023.04.003
-
Lin, Z., Trivedi, S., & Sun, J. (2023). Generating with confidence: Uncertainty quantification for black-box large language models. arXiv preprint arXiv:2305.19187. Internet of Things and Cyber-Physical Systems, Volume 3, 2023, Pages 121-154, ISSN 2667-3452, https://doi.org/10.1016/j.iotcps.2023.04.003
-
Dwivedi, Y. K., Kshetri, N., Hughes, L., Slade, E. L., Jeyaraj, A., Kar, A. K., Baabdullah, A. M., Koohang, A., Raghavan, V., Ahuja, M., Albanna, H., Albashrawi, M. A., Al-Busaidi, A. S., Balakrishnan, J., Barlette, Y., Basu, S., Bose, I., Brooks, L., Buhalis, D., … Wright, R. (2023). Opinion Paper: “So what if ChatGPT wrote it?” Multidisciplinary perspectives on opportunities, challenges and implications of generative conversational AI for research, practice and policy. International Journal of Information Management, 71, 102642. https://doi.org/10.1016/j.ijinfomgt.2023.102642